# ChatGPT实战(五):搭建私人AI对话网站(OpenAI近期开放API)
作者:华王
星球:https://t.zsxq.com/0dgMjetVg (opens new window)
学习、分享、成功;提高效率,有所收获!😄
OpenAI近期开放ChatGPT API(对话模型),Whisper API(语音转文字),开发者可将其集成到自己的产品中
地址:https://openai.com/product
# API介绍
3月2日,OpenAI宣布,开放了ChatGPT和Whisper模型的API,用户可将其集成在应用程序等产品中(不仅限于创建由AI驱动的聊天界面)。OpenAI表示,自去年12月份以来,OpenAI已将ChatGPT的成本降低了90%,现在希望通过API的方式将节省的资金赋予用户。据报道,其价格为每1000个token 0.002美元,“这比我们现有的GPT-3.5模型便宜90%”,部分原因是“一系列系统范围内的优化”。 Introducing ChatGPT and Whisper APIsDevelopers can now integrate ChatGPT and Whisper models into theirapps and products through our APl.
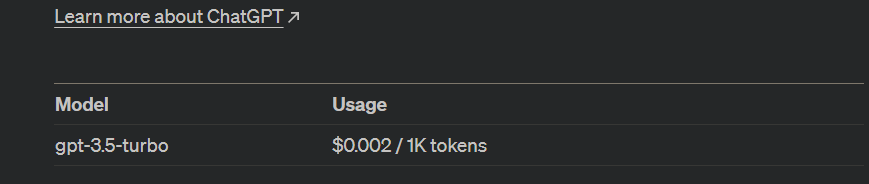
ChatGPT API (对话模型)
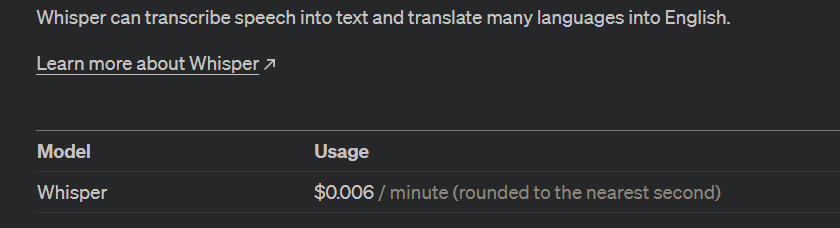
Whisper API (语音转文字)
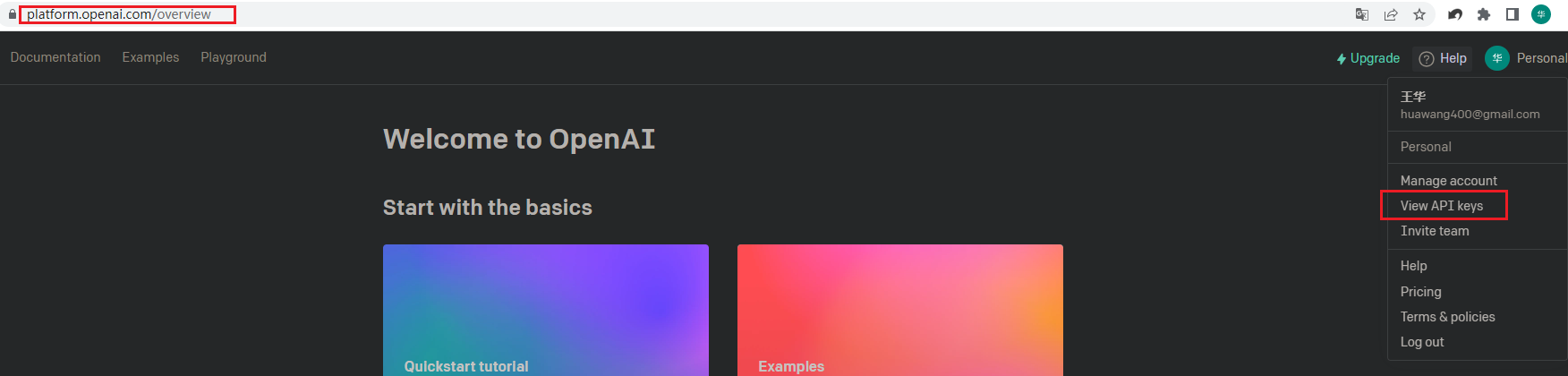
查看自己的API keys
地址:https://platform.openai.com/account/api-keys
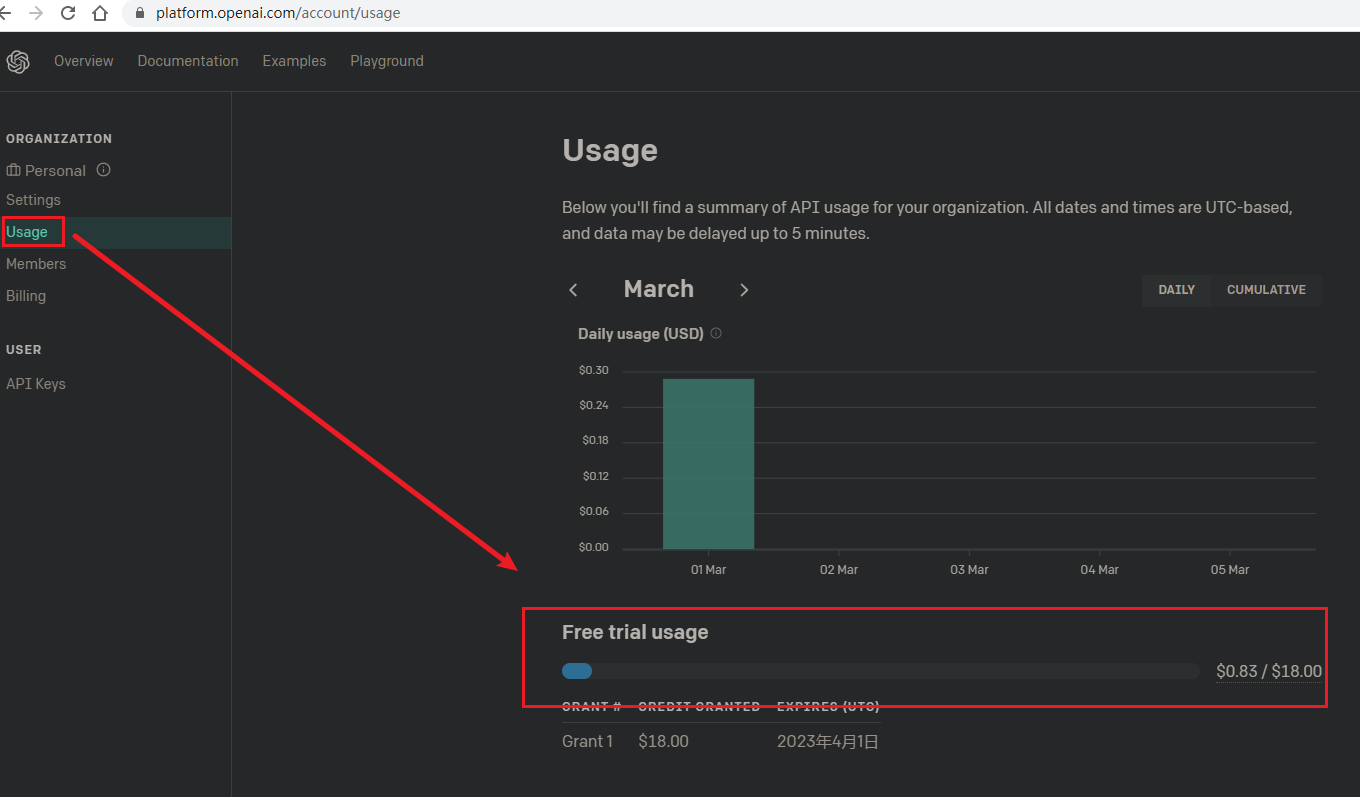
查看免费额度
地址:https://platform.openai.com/account/usage 默认注册后获得可在3个月内使用的18美元的赠送额度
# 应用构建
gpt-3.5-turbo应用场景
- 可以为你扩展更多的操作:
- 起草电子邮件或其他写作
- 编写Python代码
- 回答有关一组文档的问题
- 创建对话代理
- 为您的软件提供自然语言界面
- 在多个学科中进行教学
- 翻译语言
- 模拟视频游戏角色等等
示例:构建自己的对话机器人
import openai
openai.api_key = "your apk key"
messages = [
{"role": "system", "content": "You are a kind helpful assistant."},
]
while True:
message = input("User : ")
if message:
messages.append(
{"role": "user", "content": message},
)
chat = openai.ChatCompletion.create(
model="gpt-3.5-turbo", messages=messages
)
reply = chat.choices[0].message.content
print(f"ChatGPT: {reply}")
messages.append({"role": "assistant", "content": reply})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
目前已经有很多国外的软件基于GPT,构建了自己的AI。
示例二:简单构建ChatGPT demo 网站
github:https://github.com/llq20133100095/ChatGPTDemoAPI

git clone https://github.com/llq20133100095/ChatGPTDemoAPI.git #下载:
pip install openai #安装
pip install gradio
python app_v2.py #执行:
2
3
4
# token分析
示例(编写代码):
python调用api
import openai
openai.api_key = "sk-换成你的api key"
Prompt_52CV = """
请写一段Python程序,实现从文件夹test读取所有png格式图像,
检测图片是否含有猫和狗,如有,请把该图片保存到文件夹train中。
注意:
1.请使用开源的目标检测算法,如需要安装软件,请说明使用pip的安装命令。
2.程序运行时,请打印每张图片处理的时间,程序运行的最后,需要统计有多少张图片检测到猫和狗,并统计运行总计用时。
3.需要考虑到文件读取和写入失败的异常判断,如果出现异常,需给出提示。
4.请以python代码的格式输出。
"""
Answer = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
temperature=0,
max_tokens=3000,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
messages=[
{"role": "system", "content": "You are a useful assistant."},
{"role": "user", "content": Prompt_52CV}
]
)
# print the completion
print(Answer)
f = open('test-chatgpt-52cv.py','w',encoding='utf-8')
print(Answer["choices"][0]["message"]["content"].strip(" \n"),file=f)
f.close()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
response:
import os
import time
import cv2
import numpy as np
# 安装目标检测算法
!pip install tensorflow==2.5.0
!pip install keras==2.4.3
!pip install opencv-python==4.5.2.54
!pip install opencv-contrib-python==4.5.2.54
# 加载目标检测模型
model = cv2.dnn.readNetFromTensorflow('frozen_inference_graph.pb', 'ssd_mobilenet_v2_coco_2018_03_29.pbtxt')
# 定义类别标签
class_labels = ['background', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
# 定义检测函数
def detect_objects(image):
# 获取图像的高度和宽度
(h, w) = image.shape[:2]
# 构建一个blob,将图像缩放到固定大小,并进行归一化
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 0.007843, (300, 300), 127.5)
# 将blob输入到模型中,获取检测结果
model.setInput(blob)
detections = model.forward()
# 遍历检测结果,获取检测到的物体信息
for i in range(detections.shape[2]):
# 获取置信度
confidence = detections[0, 0, i, 2]
# 如果置信度大于0.5
if confidence > 0.5:
# 获取类别标签
class_id = int(detections[0, 0, i, 1])
# 如果类别是猫或狗
if class_id == 16 or class_id == 17:
# 计算物体的边界框坐标
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# 绘制边界框和类别标签
label = "{}: {:.2f}%".format(class_labels[class_id], confidence * 100)
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 255, 0), 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(image, label, (startX, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return image
# 定义读取文件夹中所有png格式图像的函数
def read_images(folder_path):
images = []
for filename in os.listdir(folder_path):
if filename.endswith('.png'):
images.append(os.path.join(folder_path, filename))
return images
# 定义保存图像的函数
def save_image(image, save_path):
try:
cv2.imwrite(save_path, image)
except Exception as e:
print('保存图像失败:', e)
# 定义主函数
def main():
# 定义文件夹路径
test_folder = 'test'
train_folder = 'train'
# 获取所有png格式图像的路径
images = read_images(test_folder)
# 定义计数器和时间戳
count = 0
start_time = time.time()
# 遍历所有图像
for image_path in images:
try:
# 读取图像
image = cv2.imread(image_path)
# 检测图像中是否含有猫和狗
result = detect_objects(image)
# 如果检测到猫和狗,保存图像到train文件夹中
if 'cat' in result or 'dog' in result:
save_path = os.path.join(train_folder, os.path.basename(image_path))
save_image(result, save_path)
count += 1
# 打印处理时间
print('处理图像{}用时:{:.2f}s'.format(image_path, time.time() - start_time))
except Exception as e:
print('处理图像{}失败:{}'.format(image_path, e))
# 打印统计信息
print('共检测到{}张图片含有猫和狗,总用时:{:.2f}s'.format(count, time.time() - start_time))
if __name__ == '__main__':
main()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
这段程序运行测试,不过看着像那么回事。
token花费
ChatGPT的定价为每1千个tokens收费0.002美元,大约相当于700个单词。我们需要注意的是,输入和输出文本都将消耗tokens。可以做简单计算一下,如果您有18美元的免费额度,则可以输入和输出总计6300000个英文单词。对于个人用户而言,免费账户可以使用很长一段时间。 考虑到我们主要还是以中文提问,所以我们来看一下耗费了多少tokens。每次的响应里,都有使用了多少token的统计,比如上面的代码调用后返回的结果里面有:
"usage": {
"completion_tokens": 1348,
"prompt_tokens": 198,
"total_tokens": 1546
}
2
3
4
5
提问部分用了198个tokens,总计耗费1546个tokens,花费0.003美元,0.02元人民币!
最后 可以想象,我们接下来可能访问的网站,都有ai的身影
