# 【AI绘画】Stable Diffusion实战(三):全模型总结和资源汇总(详解版)
作者:华王
星球:https://t.zsxq.com/0dgMjetVg (opens new window)
学习、分享、成功;提高效率,有所收获!😄
在Stable Diffusion的ui界面有大量的模型选项(如下),同时AI绘画中大小模型眼花缭乱,层出不穷;那么如何理解和使用这些模型呢,本文做一个详细的解释
# 工具和文献参考
1 SD 模型解析
地址:https://spell.novelai.dev/
从 Stable Diffusion 生成的图片读取 prompt / Stable Diffusion 模型解析 功能:查看模型类型;文件大小;模型用法

2 模型下载:
1 Civitai: civitai.com/ 2 weUI资源站:www.123114514.xyz/models 3 huggingface:huggingface.co/models
以上是主流SD模型下载站点,基本需要的模型都可以在里面找到
3 提示词模板
1 词图PromptsTools: prompttool.com/NovelAI 2 魔咒百科词典:aitag.top/ 3 finding.art:finding.art/ 4 NovelAI tag生成器 :wolfchen.top/tag/ 5 AI魔导树:https://aimds.top/home 6 Danbooru 标签超市:https://tags.novelai.dev/
4 github以及文档地址
github: github.com/AUTOMATIC1111/stable-diffusion-webui wiki文档: github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/ 模型使用: github.com/civitai/civitai/wiki/How-to-use-models#fine-tuned-model-checkpoints-dreambooth-models
# 模型概论
模型可以分为两大类:大模型 和 小型模型(微调大模型)
小型模型:Textual inversion (常说的Embedding模型)、Hypernetwork模型、LoRA模型(最常用)。 VAE模型:类似滤镜一样的东西,他会影响出图的画面的色彩和某些极其微小的细节。大模型本身里面就自带 VAE 的,但是一些融合模型的 VAE 烂掉了 (典型:Anything-v3),需要外置 VAE 的覆盖来救救
说明:由于 Textual Inversion 和 HyperNetworks 的训练难度较大,效果也通常不尽如人意,目前并没有成为模型微调的主流选择,目前微调主要使用的还是 LoRA模型 模型种类的辨别 可使用上面的第一个工具SD 模型解析 ,只需把模型拖进来就行
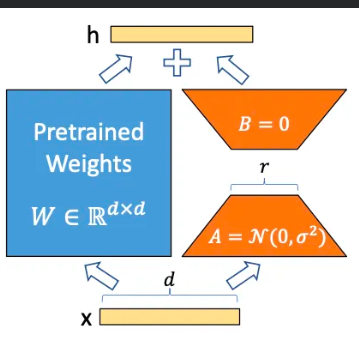
大型语言模型通常有几百B甚至几千B的参数量。如果直接拿这些大型模型来微调以执行特定任务,那么成本高、速度慢、负担重,性价比太低。因此,LoRA这种方法应运而生。它通过将原来的大型语言模型冻结,然后在外部使用一个小插件来进行微调,而不是直接修改原有的大型模型。在完成微调后,再将它们合并在一起。
loro模型介绍:
We propose Low-Rank Adaptation, or LoRA, which freezes the pre- trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable pa- rameters for downstream tasks. 我们提出了低秩自适应(Low-Rank Adaptation, LoRA),它冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层,极大地减少了下游任务的可训练参数的数量。
其实就是加速微调:通过“矩阵分解”的方式,只需要微调更少的参数。 论文:https://arxiv.org/abs/2106.09685
# 模型种类及使用方法
具体使用可参考开头第4点文档
模型后缀名: ckpt,pt,pth,safetensors; 前三种是 pytorch 的标准模型保存格式,有一定的安全风险; safetensors 格式更加安全;
1 大模型(基础模型) 大模型:常见格式为 ckpt,大小在GB级别,常见有 2G、4G、7G模型; 存放目录:/models/Stable-diffusion; 使用:webui 左上角选择对应的模型
VAE 模型:常见格式为.pt; 存放目录:models/VAE;
2 Embedding (Textual inversion) 常见格式为 pt、png图片、webp图片,大小在 KB 级别 存放目录:/models/ embedding;
3 HyperNetworks
微调一个额外的网络结构,作用于 diffusion 过程的 attention 结构上常见格式为 pt。大小一般在几十兆到几百兆不等,有些可达到 GB 级别 存放目录:models/hypernetworks 使用:从设置中的Hypernetwork输入字段中选择
4 LoRA(最常用) 常见格式为 pt、ckpt,大小8m~144m不等 存放目录:models/lora 使用:show extra networks按钮,到Lora选项卡并根据需要刷新;或者 点击一个模型以后会向提示词列表添加类似这么一个tag, lora:模型名:权重
# 模型推介与展示
模型众多原因:不同的模型可以带来不同的画风(人物/物体/风景/动作等等)
大模型: 生成多风格的Anythin4.5,生成逼真3D幻想风格的DreamShaper
1 ChilloutMix(基础真人大模型,但要搭配lora)

2 Anything v5(多风格的动漫模型)

3 stable-diffusion 1.5 2.0:较为通用的、现实模型,无法画出二次元图片
4 majicMIX(真人大模型)
基于KanPiroMix + XSMix + ChikMix三个模型融合而来,搞颜色的能力也极强哈哈;

4 GhostMix(2.5D大模型)

5 MIX-Pro(动漫风格合并模型)

6 Night Sky(极致画质和超大图像尺寸)

7 DreamShaper(生成逼真3D幻想风格)

下期给大家推荐一些好用的LORA模型
以上,创作不易,有用的话请点个关注点个赞吧,感恩!
