# 【AI绘画】StableDiffusion 自定制模型(一): 四种模型优化原理篇
作者:华王
星球:https://t.zsxq.com/0dgMjetVg (opens new window)
学习、分享、成功;提高效率,有所收获!😄
为什么要训练自己的模型?训练自己的模型可以在现有模型的基础上,让AI懂得如何更精确生成/生成特定的风格、概念、角色、姿势、对象。
一个血的事实是:好的模型随便出的图,大多超过你费尽心思百遍的Prompt所输出的图,所以微调优化属于自己的定制化模型也是挺重要的
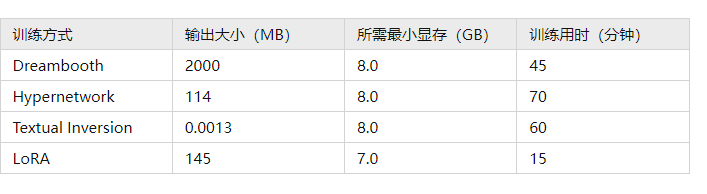
本篇介绍目前四种主流微调(Fine Tuning) Stable Diffusion模型的方法(Dreambooth, LoRA, Textual Inversion, Hypernetwork),让你对模型训练的原理与过程有个认知、熟悉四种方式优缺点,从而选择适合的微调方式
训练模型至少需要10GB的VRAM,也就是RTX3060等级以上的GPU;Nvidia RTX3060以上等级的GPU,50张图片的小模型训练时间约1~3小时
参考:
stable-diffusion-art.com/how-stable-diffusion-work/ https://zhuanlan.zhihu.com/p/612992813 https://mp.weixin.qq.com/s/9Dw2GYkg6b1vvKKyJQ-3TA
# 概述
模型影响结果,基于哪个现有模型,以及喂给AI学习的图片品质,还有训练时的参数,都会影响模型训练结果
目前常用的模型微调方法,包含以下四种模式
1 Dreambooth:微调整个网络参数 2 LoRA:通过矩阵分解的方式,微调少量参数,并加总在整体参数上 3 Textual Inversion:只微调新词对应的 embedding 4 HyperNetworks:微调一个额外的网络结构,作用于 diffusion 过程的 attention 结构上
目前主流训练方式为前两种 Dreambooth 和 LoRA(以及 LoRA 的变体 LyCORIS);训练时间与实用度而言,目前应是 LoRA > HyperNetwork > Embedding
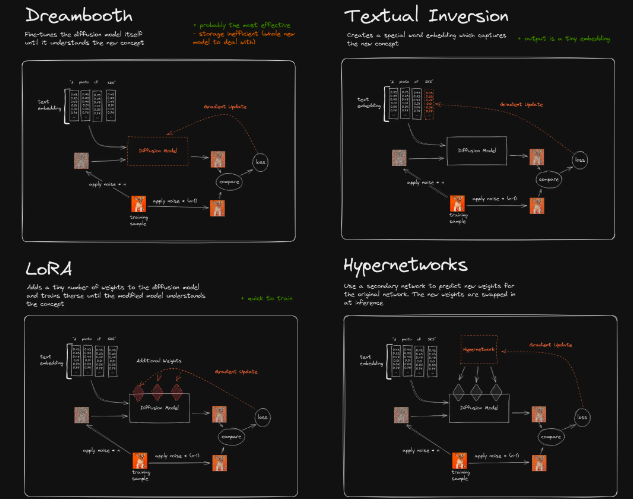
Dreambooth最核心的一点,就是它将训练出一个完整的新模型出来。因此从效果上来说,他是用于将一个新的概念添加到SD模型中最合适的训练方案。它将占据相当大的存储空间,不过从根上看,Dreambooth还是最好的。 如果硬件条件许可的话,搜集大量图片训练特定领域的checkpoint大模型最好(对比stable Diffusion 1.5版的模型输入了23亿张图片,网络上其他人训练至少几万张图片;)
# Dreambooth
资源
插件: github.com/d8ahazard/sd_dreambooth_extension 论文: https://arxiv.org/abs/2208.12242
Dreambooth通过直接修改整个原始模型来对模型输出结果进行调校,微调整个网络参数
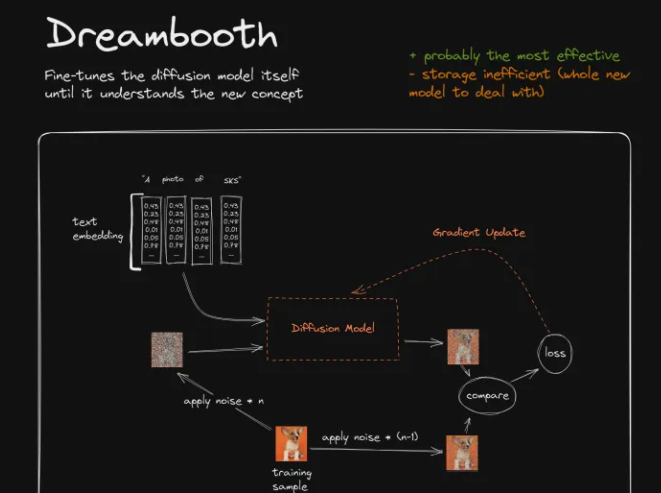
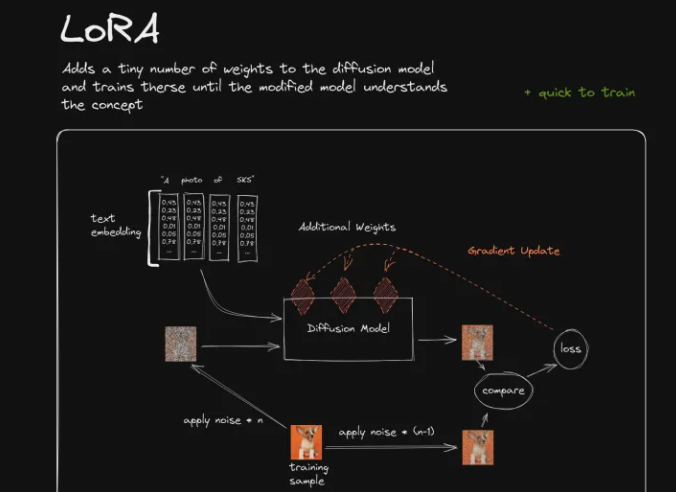
例如如上,Dreambooth所训练的事情,就是将柯基犬的图片与关键词SKS建立起关联关系
训练的过程:
- 给训练图片添加n步噪声,使其变成较为嘈杂的图片(测试图左侧的噪声图)
- 另外再给训练图片添加较少一点的噪声(n-1),使其成为一张校准图片(测试图右侧的图片)。
- 然后我们来训练SD模型以左侧较嘈杂的图片作为输入,再加上特殊关键词指令的输入,能输出右侧较为清晰的图片。
- 一开始,由于模型可能根本就不识别新增的特殊关键词SKS,他可能输出了一个不是很好的结果。此时我们将该结果与目标图片(右侧较少噪声的图片)进行比较,得出一个loss结果,用以描述生成图像与目标图像的差异程度。
- 接着Dreambooth会做一步被称为Gradient Update的事情。有关Gradient Update的事情实在是过于复杂了,你可以简单理解为,如果Loss高的话它将惩罚模型,如果Loss低的话它将奖励模型。
- 当训练重复了一段时间后,整个模型会逐渐认识到:当它收到SKS的词语输入时,生成的结果应该看起来比较像训练者所提供的柯基犬的图片,由此我们便完成了对模型的调校。
插件使用:
github.com/d8ahazard/sd_dreambooth_extension
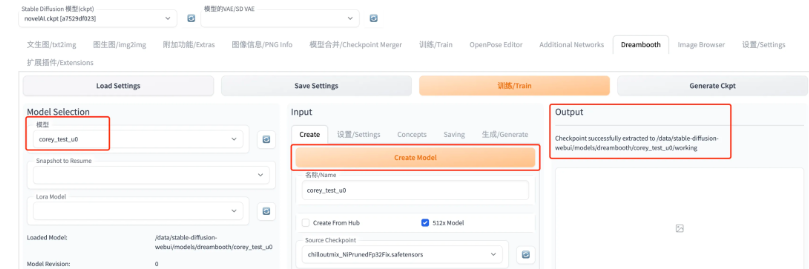
1: Create Model
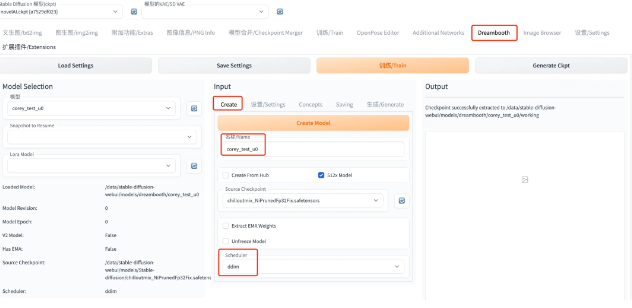
Source Checkpoint 初始化模型(ckpt文件模型);Scheduler 采样器,就是选择扩散模型的形式; 都设置好之后,点击黄色的 Create Model,稍等在 Output 处可以看到 successfully 的日志,以及在左边 Model Selection 处可以看到自己刚 Create 出来的模型
成功标志:
2: 设置相关参数
参考前文提到的 git官方说明
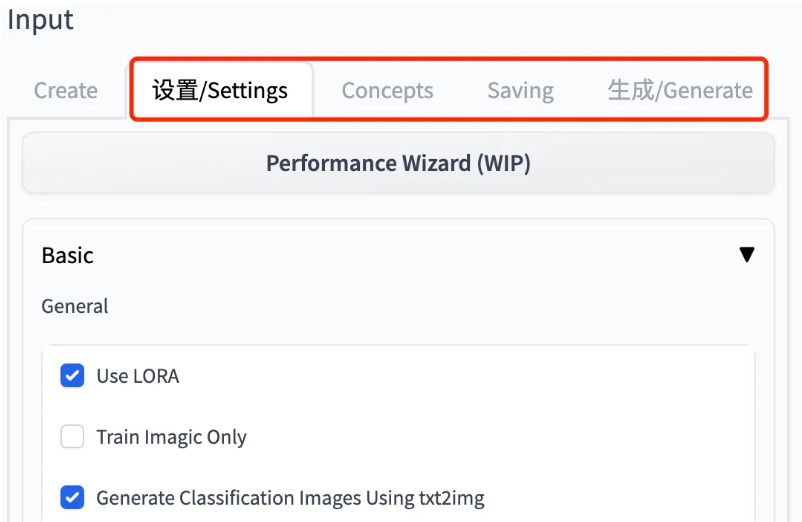
1 Settings 部分主要需要设置是否采用 LoRA、Epochs、模型保存策略、Batch Size、学习率等 2 Concepts 部分主要有两个,一个是数据路径,另一个是 class 和 prompt。所谓 prompt,就是目标样本对应应该输入什么提示词;而 class 补充一些与目标主体属于同一类别但不是同一个体的样本,计算 class-specific prior preservation loss 的那部分样本的类别(prompt),模型会根据此生成一部分图片,作为微调样本。 3 Saving 就是.ckpt 文件、loRA 小模型、扩散模型分别以什么样的策略进行保存。 4 Generate 部分主要设置模型生成
3: 训练和监控 击上面橙色的 Train,就可以开始训练了;查看日志/WebUI 的 Output 界面查看下训练过程中的 loss,以及模型生成出来的图片
# lora
资源:
代码: github.com/microsoft/LoRA 论文: arxiv.org/abs/2106.09685
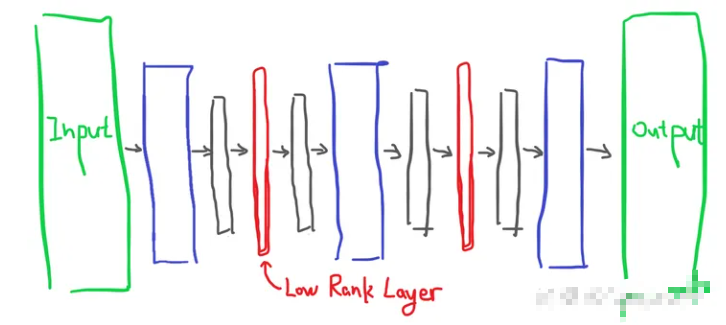
全称Low Rank Adaption,LoRA训练相较于Dreambooth更快且使用更少的VRAM,其数据大小相较于完整模型要小很多(150M左右);AI模型的内部实现如上
LoRA采用的方式是向原有的模型中插入新的数据处理层,这样就避免了去修改原有的模型参数,从而避免将整个模型进行拷贝的情况,同时其也优化了插入层的参数量,最终实现了一种很轻量化的模型调校方法
使用: 1 在 Dreambooth 的 Settings 中勾选“Use LoRA” 2 通过脚本直接训练 LoRA 模型(推荐也是主流方式)
后期会做一个具体lora训练的示例,记得关注不迷路
# Textual Inversion
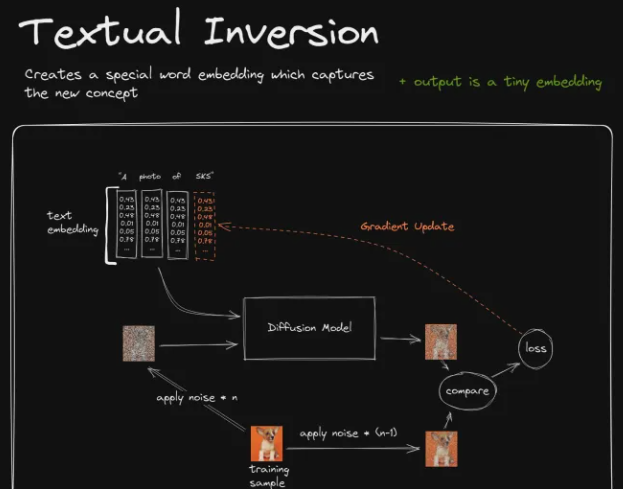
教程 1:https://www.bilibili.com/video/BV1pm4y1A7rn 教程 2:https://www.bilibili.com/read/cv19040576
Gradient Update将作用于SKS在语言处理模型中对应的参数向量(Embedding Vector);通过训练,Textual Inversion为SKS关键词找到了一个最合适的向量
参数向量简单来说就是关键词SKS经过语言模型处理后所得到的一个向量数据,后续的Diffusion Model将使用这些由输入指令“A photo of SKS”转换而来的一组向量数据作为实际的输入参数,来影响并指导Diffusion生成图像的过程
# Hypernetwork

用的很少,文档也很少,和lora差不多,具体原理也不是很清楚。。
以上就是SD四种微调方式,市面上了大模型基本就是来源这些方式,之后会真实的使用lora训练自己的模型,整合各种训练时候的坑,下期见
